PROJECT GOAL : 중고차 가격 예측을 위한 머신러닝 모델링
[프로젝트 개요]
- 프로젝트 명 : 영국 내 현대 중고차 시세 예측 모델링(현대 중고차 서비스 해외 진출을 위한 가격 예측 모델 비교)
- 기간 : 2025년 1월 24일 ~ 2025년 2월 6일
- 인원 : 팀 (5명)
- 역할 : 프로젝트 흐름 기획, 데이터 전처리를 위한 EDA , 머신러닝 학습 및 성능 비교
- 작업 도구 : 파이썬(pandas, sklearn-선형회귀, 랜덤포레스트, XGBoost)
[데이터 개요]
출처 : https://www.kaggle.com/datasets/adityadesai13/used-car-dataset-ford-and-mercedes/data
100,000 UK Used Car Data set
100,000 scraped used car listings, cleaned and split into car make.
www.kaggle.com
- 총 13개의 테이블 존재

- unclean 데이터는 전처리 전 데이터
- cclass & focus는 수집 시점도 다르며, merc와 ford 테이블에서 중복이 있으므로 분석 대상에서 제외
- 최종적으로 9개의 브랜드 데이터만 활용(컬럼 구성은 동일)
브랜드명.csv : 브랜드별 중고차 정보
| Columns | 설명 | |
| model | 차량 모델 | |
| year | 차량 연식 | |
| price | 차량 가격 | 단위 : 파운드 |
| transmission | 변속기 | |
| mileage | 주행거리 | 단위 : 마일 |
| fuelType | 연료 | |
| tax | 자동차세(도로세) | 단위 : 파운드 |
| mpg | 연비 | 단위 : mpg(mile per gallon) |
| engineSize | 엔진 크기 | 단위 : 리터(예상) |
[분석 목적 및 방법]
1. 분석 목적
- 1차 : 전체 브랜드 대상 분석 및 모델 학습(방향성 부재)
- 2차 : 스토리 라인 기획 및 타겟 브랜드 대상 분석 및 모델 학습(방향성 수립)
2. 분석 방법
① 시장 분석
- 영국 내 자동차 시장, 특히 현대차 현황 파악을 위한 시장분석
② EDA(현대차 vs 영국 내 선호 브랜드 3사)
- 현대차 데이터 파악 및 선호도 상위 브랜드 대비 현대차의 시장 포지션 확인을 위한 분석
③ 머신러닝 학습 및 성능 비교
- 정확도 높은 중고차 가격 예측을 위한 회귀 분석 기반의 다양한 머신러닝 학습
[분석 과정 및 결과]
1. 시장 분석
- 영국 내 현대차 현황을 조사한 결과, 2020년대 부터 현대차의 판매량 및 점유율이 높아지는 추세를 확인하였고, 이를 기반으로 중고차 수요도 함께 증가할 것으로 예상
- 영국에서 차량 브랜드 중 가장 선호도가 높은 상위 3사를 파악하였고, 폭스바겐/포드/복스홀이 꾸준히 상위에 올라옴
- 국내 현대 중고차 서비스를 운영하는 현대차그룹, 현대캐피탈 등은 글로벌 확장의 비전을 가지고 있는 상황으로, 영국 현대 중고차 서비스 진출을 위한 가격 예측 모델 개발을 상황을 가정함
2. EDA
① 현대차 vs 상위 3사
- 상위 3사의 중고차 가격대와 현대 중고차의 가격대 비교 등
- 담당 파트 X > 스토리 라인에 맞는 EDA 구성이 이루어지지 않아 아쉽다는 피드백으로 인해 추후 디벨로 해볼 예정
① 현대차 EDA(학습용 모델 전처리)
- model(범주형 변수) : 10개 이하 차량 모델 제거

- year(수치형 변수) : 불가능한 차량 연식 없음, 데이터 유지

- price(수치형 변수) : 가격의 최대값은 출고가(모델 I10)를 뛰어넘는 수치로 삭제, 모델별 가격 분포를 확인한 결과 각 모델별 최대값이 출고가와 비슷한 수준으로 확인되어 데이터 유지


- transmission(범주형 변수) : Other은 기타 값으로 특성을 파악할 수 없고, 수가 너무 적어 삭제

- mileage(수치형 변수) : 이상치 값들의 평균 차량 연식은 8년 이상으로 집계, 상한 한계선인 64,870마일 이상(최대값인 140,000마일의 연식은 2008년으로 12년)의 주행거리를 이상치로 보기 어려움
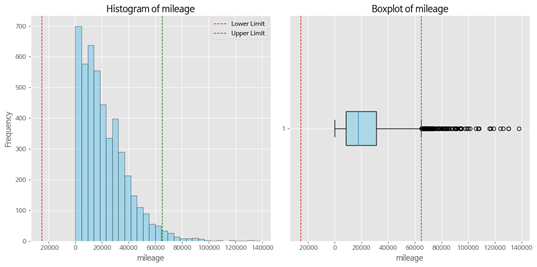
- fuelType(범주형 변수) : Other은 기타 값으로 특성을 파악할 수 없고, 수가 너무 적어 삭제

- tax(수치형 변수) : 구간별로 나뉘어 분포하는 특징, 실제 영국 도로세는 구간별로 부과되는 사실에 기반하여 범주형 변수로 변환함(tax 중앙값 기준 low/high로 재설정)

- mpg(수치형 변수) : 일반적인 차량 연비와 비교했을 때, 이상치는 가능성이 낮은 수치이며, 특히 최대값으로 나타나는 수치는 테스트 환경에서 나오는 수준으로 현실적인 수치가 아닌 것으로 판단하여 삭제

- engineSize(수치형 변수) : 불가능한 수치로 판단할 수 없어 데이터 유지

3. 머신러닝 학습 및 성능 비교
① 학습 단계 요약
- 베이스라인 모델 학습 - 차원 축소한 데이터 적용 - 앞선 EDA 기반 이상치 제거 데이터 적용 - 파생변수를 추가한 데이터 적용 - 하이퍼 파라미터 튜닝
② 학습 조건
- 선형회귀, 랜덤포레스트, XGBoost 세가지 모델 학습
- 공통적으로 범주형 변수는 원-핫 인코딩을 적용하고, 5-Fold 교차검증을 수행하여 과적합 확인
- 선형회귀 모델의 경우, 변수간 스케일 차이를 줄이기 위해 독립변수는 Standard 스케일링, 종속변수는 로그변환 후 학습하고, 지수함수로 종속변수 복원 후 성능지표를 도출함
③ 학습 단게별 결과 요약
- ⓐ 베이스라인 : 교차검증 결과 과적합 의심 모델은 없었음
- ⓑ 차원 축소 : 상관관계가 높은 year와 mileage를 연 평균 주행거리로 함축하여 차원을 축소하여 학습, 베이스라인보다 성능이 떨어지는 결과 확인
- year와 mileage는 강한 선형관계에 있으나, 같은 연식의 차량에서도 주행거리는 넓게 분포할 수 있다는 중고차 특성이 반영되어 무조건적인 차원 축소가 성능 개선의 결과를 가져오지 않은 것으로 보임
- ⓒ EDA 기반 이상치 제거 : 앞선 과정은 페기, 이상치를 제거한 데이터 적용 결과 세가지 모델 모두 베이스라인 대비 성능 지표가 개선됨(과적합 또한 없음)
- ⓓ 파생변수 추가 : 선형회귀 모델은 성능이 미세하게 개선되었으나 랜덤포레스트와 XGBoost 모델 성능은 미세하게 저하됨(과적합 없음)
- ⓔ 하이퍼 파라미터 튜닝 : 이상치를 제거한 3번째 단계에서 하이퍼 파라미터 튜닝(GridSearchCV 활용)을 수행한 결과, 튜닝 전 모델 대비 성능이 소폭 개선되었음


⑤ 최종 성능 비교 요약

- 세가지 모델 모두 각 단계를 거치며 점차 성능이 개선된 것을 확인함
- 세 모델 모두 최적 파라미터가 적용된 모델의 성능이 가장 좋음
- 가장 성능이 좋은 모델은 파라미터 튜닝이 완료된 XGBoost 모델로 선정, 모델의 설명력(R^2)은 0.964로 설명력이 높으며, MAE 지표를 기준으로 해당 모델에서 평균적으로 780.3파운드의 오차를 보임
[배운 점]
모델 학습을 위해서는 집요한 이상치 조사가 필요하다
- 통계적인 이상치는 IQR 기법으로 파악할 수 있지만, 실제로 그 값이 이상치인지는 구체적인 조사가 필요함
- 이번 프로젝트처럼, 차량의 평균 수명은 주행거리 20만km라고 통요되고 있지만, 10여년 간 주행한 차량은 주행거리가 그 이상이 되는 경우도 충분히 가능함
- 연비 또한 차량 모델별 가능 범위를 파악해야하며, 가격 또한 중고차 가격이라는 점에서 출고가와 큰 차이가 없는지 확인할 필요가 있음
- 이처럼 통계적 이상치와 실제 이상치는 다른 것이므로 학습용 데이터를 구축하기 위해서는 많은 조사가 필요함
머신러닝은 무조건 이렇게 적용해야한다는 매뉴얼이 없다(고려할 요소가 넘쳐난다.. 수많은 경우의 수를 비교하는 과정)
- 처음 모든 브랜드의 중고차 데이터를 이용하여 선형회귀 모델을 학습했을 때, R^2 값이 음수가 나오는 비정상적인 결과가 나왔음
- 차량 모델은 크기나 순서가 있는 범주형 변수가 아니기 때문에 원-핫 인코딩을 적용하였으나, 이로 인해 200여개 모델이 모두 변수로 변환되면서 차원의 저주가 발생한 것으로 해석됨
- 차원 축소를 위해 종류가 많은 범주형 변수인 모델과 브랜드에 라벨인코딩을 적용하였고, 선형회귀 모델 학습 결과 정상적인 성능지표가 도출됨
- 이처럼 이론상으로 크기나 순서가 없는 범주형 변수는 원-핫 인코딩을 적용하는 것이 맞으나, 모델을 학습하는 과정에서 그 이론이 적용되지 않으면 다양한 경우를 비교할 필요가 있음
[향후 보완점]
- EDA는 좀 더 스토리라인에 맞춰 분석(스토리가 있는 분석이거나, 데이터 전처리 근거를 위한 컬럼별 EDA를 자세하게 넣을 필요가 있음)
- 그래프를 잘 보이게 하는 방법을 고민해야 함(발표시 시각적 표현)
- 그래프를 이용한 시각화에 집착하지 않고, 때로는 기술통계 수치를 직접적으로 보여주는 것이 더욱 효과적이기도 함(box plot이 오히려 한번에 이해하기 어려운 것 같은..)
'데이터 부트캠프 - Project' 카테고리의 다른 글
| [파이썬 기초 분석 프로젝트] 프로모션 성과 분석 및 향후 프로모션 제안 (0) | 2025.01.07 |
|---|---|
| [SQL 분석 프로젝트] 이커머스 이벤트 히스토리 분석 (1) | 2024.12.10 |