Today's Goals
1. API로 데이터 수집하기
2. 통계학 개인과제 해설
데이터 수집을 이야기할 때 항상 오픈API에 대해 들었는데,
어떤건지, 어떻게 하는지 궁금했던 차에 라이브 세션으로 배울 수 있어서 재밌었다!
머신러닝은 아직 감이 잡히지 않은 것 같다.
올 초에 분명 예측 모델을 활용해 봤었는데, 그 땐 대체 어떻게 한건지...
1. 오픈API에서 데이터 수집
[공공데이터 포털에서 api 데이터 수집하기]
import requests
import json
import pandas as pd
url = 'http://apis.data.go.kr/1160100/service/GetFinaStatInfoService_V2/getBs_V2'
params = {
'pageNo': 1,
'numOfRows': 100,
'resultType': 'json',
'serviceKey': 'CInqflqEroMBIvwzFgjXQJmsywE6qccC7DzY9BmyjB8inNR88bJjlwr2NzkrLN5VZKyMf39GNtGDHdloYAKJWw=='
}
response = requests.get(url, params=params)- 데이터를 불러올 수 있는 url을 설정하고, 파라미터 값을 지정함
- 파라미터는 서버에 특정한 요청을 전달하는 것으로, 필요한 데이터의 조건을 설정하거나, 응답 형식을 지정하거나, 필터링 등을 수행함(몇 행을 가져올건지, 어떤 타입의 데이터를 가져올건지, api 사용 키는 뭔지 등등)
- requests.get()을 통해 데이터를 불러옴
data = response.json()- 위와 같은 과정으로 HTTP 응답 본문을 JSON 데이터로 디코딩함(이 경우에만 사용되는 것이 json())
- 이전에 json형태로 컬럼값이 저장된 것을 전처리 했었는데, 그 때 사용한 json.loads와는 다름
- json.loads()는 문자열로 존재하는 json 데이터를 파이썬 객체(딕셔너리 등) 형태로 이용하는 방법임
- json.load()는 파일 형태로 존재하는 json 데이터를 파이썬 객체(딕셔너리 등)로 이용하는 방법임
clean_data = json.dumps(data, indent=4, ensure_ascii=False)
print(clean_data)- 불러온 데이터를 json 문자열 형태로 보기 위해 json.dumps() 사용(이 결과를 loads를 활용하여 딕셔너리 변환하는 것)
- 문자열로 변환하면서 한글은 아스키 문자로 변환될 수 있는데, 이를 방지하기 위해 ensure_ascii=False를 설정해줌(유니코드 문자 오류 방지)
- indent는 들여쓰기 수준을 설정해주는 것
- 최종적으로 확인한 결과는 아래와 같음

item = data['response']['body']['items']['item']
df= pd.DataFrame(item)
df- 확인된 데이터 구조에 따라, 우리가 필요한 데이터프레임은 item 안에 있음
- item이하 값들을 추출하여 데이터프레임화 한 코드임

[최종 코드]
import requests
import json
import pandas as pd
url = 'http://apis.data.go.kr/1160100/service/GetFinaStatInfoService_V2/getBs_V2'
params = {
'pageNo': 1,
'numOfRows': 100,
'resultType': 'json',
'serviceKey': 'CInqflqEroMBIvwzFgjXQJmsywE6qccC7DzY9BmyjB8inNR88bJjlwr2NzkrLN5VZKyMf39GNtGDHdloYAKJWw=='
}
response = requests.get(url, params=params)
data = response.json()
#전체 데이터 json 형태 확인
# clean_data = json.dumps(data, indent=4, ensure_ascii=False)
# print(clean_data)
item = data['response']['body']['items']['item']
df= pd.DataFrame(item)
df
[처음부터 item 이하 값만 불러올 수 있다?]
- 정보를 제공하는 페이지를 확인하면 아래와 같은 값을 확인할 수 있음

- 코드에서 사용한 url의 가장 끝 부분을 위의 경로로 바꾸면 해당하는 파트의 이하값만 가져올 수도 있음
2. 통계학 개인과제 (해설)
[numpy와 pandas에서 구하는 표준편차의 차이점 - 함정이다!]
- 기본적인 표준편차를 구하는 식은 다음과 같음
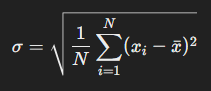
- 이는 모집단의 표준편차를 구하는 식임
- 표본의 표준편차를 구하는 식은 아래와 같은데, 표본 평균을 구할 때 이미 하나의 자유도를 소모했기 때문임(이렇게 N을 조정하는 것을 Bessel's correction(베셀의 보정)이라고 함)
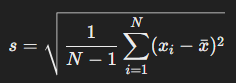
- 따라서 numpy를 이용하여 표본의 표준편차를 구하려면 다음과 같은 코드를 이용함
std_a = np.std(com_a, ddof=1)- ddof를 설정하면 표준편차를 구하는 식에서 N을 N-ddof로 조정하게 됨, 즉, ddof=1은 표본의 표준편차에 해당
- pandas를 이용하여 표준편차를 구하는 경우, 기본적으로 표본이 기준이기 때문에 ddof 설정 필요 없음(다만 모집단의 표준편차를 구한다면 ddof=0 필요)
'데이터 부트캠프 - Today I Learned' 카테고리의 다른 글
| [스파르타 내일배움캠프 / 데이터 분석 트랙] TIL(Today I Learned)_9주차_25.01.20 (0) | 2025.01.20 |
|---|---|
| [스파르타 내일배움캠프 / 데이터 분석 트랙] WIL(Weekly I Learned)_8주차 (0) | 2025.01.19 |
| [스파르타 내일배움캠프 / 데이터 분석 트랙] TIL(Today I Learned)_8주차_25.01.16 (0) | 2025.01.16 |
| [스파르타 내일배움캠프 / 데이터 분석 트랙] TIL(Today I Learned)_8주차_25.01.15 (0) | 2025.01.15 |
| [스파르타 내일배움캠프 / 데이터 분석 트랙] TIL(Today I Learned)_8주차_25.01.14 (0) | 2025.01.14 |