Today's Goals
1. SQL 꾸준한 연습 - SQL 코드카타, QCC 대비 복습
2. 파이썬 익숙해지기 - 파이썬 코드카타, 셀프 실습 데이터 파악, pandas 라이브 세션
이번주 진도가 조금 빠르게 끝나서 개인적으로 실습 연습도 할 겸 팀원들과도 함께 할 겸데이터를 두개 골라봤다
간단히 시각화를 시도해봤는데, 한 그래프 안에 여러 선그래프를 비교하고 싶었다.
그거 어케하는뎅...
블로그와 공식문서를 뒤적이며 공부하다보니 for문을 이렇게 쓰게되네 싶더라
파이썬 문법 공부 다 이유가 있었따
1. SQL 연습
SQL 코드카타
[if(,1,0) 처리를 하지 않아도 알아서 T/F 결과는 1,0으로 해석하는 똑똑이 SQL]
# 나의 답안
select date_format(trans_date, '%Y-%m') as month,
country,
count(id) as trans_count,
sum(if(state='approved',1,0)) as approved_count,
sum(amount) as trans_total_amount,
sum(if(state='approved',amount,0)) as approved_total_amount
from Transactions
group by date_format(trans_date, '%Y-%m'), country
# IF 사용하지 않아도 실행되는 답안
select date_format(trans_date, '%Y-%m') as month,
country,
count(id) as trans_count,
sum(state='approved') as approved_count,
sum(amount) as trans_total_amount,
sum((state='approved') * amount) as approved_total_amount
from Transactions
group by date_format(trans_date, '%Y-%m'), country- 따로 조건에 따라 1과 0을 할당해주지 않아도 MySQL은 T/F를 판별하면서 자체적으로 1/0으로 해석함
- 하지만 처리 속도 자체는 위가 더 좋았..음..
[SQL도 평균 계산 함수가 있어요ㅠㅠㅠ AVG]
- 주어진 컬럼들을 이용하여 평균값을 구하는 문제가 나올 때, AVG로 쉽게 할 수 있음에도 count, sum 등을 써서 복잡한 식을 만드는 경우가 많음
- AVG가 있다는 것 잊지 말기
# 처음 답안 --처리속도 가장 좋음
with first_order as (select customer_id, min(order_date) as first_order_date
from Delivery
group by customer_id
)
select round((sum(if(b.first_order_date = a.customer_pref_delivery_date,1,0)) / count(*) *100),2)
as immediate_percentage
from Delivery a
join first_order b
on a.customer_id = b.customer_id and a.order_date = b.first_order_date
# avg 함수 쓰기
with first_order as (select customer_id, min(order_date) as first_order_date
from Delivery
group by customer_id
)
select round((avg(if(b.first_order_date = a.customer_pref_delivery_date,1,0))*100),2)
as immediate_percentage
from Delivery a
join first_order b
on a.customer_id = b.customer_id and a.order_date = b.first_order_date
# 쿼리 짧게
select round(avg(order_date = customer_pref_delivery_date)*100, 2) as immediate_percentage
from Delivery
where (customer_id, order_date) in (
Select customer_id, min(order_date)
from Delivery
group by customer_id
);
2. Python 연습
Python 코드카타
[리스트 안의 요소를 모두 붙여 하나의 문자열로]
- ''.join() : 문자열로 이루어진 리스트 안의 요소를 하나의 문자열로 붙여서 반환해줌
- '_'.join()을 하면 a_b_c라는 문자열이 생기고, '*'.join()을 하면 a*b*c*라는 문자열이 생김
https://blockdmask.tistory.com/468
[python] 파이썬 join 함수 정리 및 예제 (문자열 합치기)
안녕하세요. BlockDMask입니다. 오늘은 파이썬에서 리스트를 문자열로 일정하게 합쳐주는 join 함수에 대해서 알아보려고 합니다. join 함수는 문자열을 다룰 때 유용하게 사용할 수 있는 함수이니
blockdmask.tistory.com
[True/False가 할당된 변수를 따로 지정하지 않아도 조건을 Return하면 T/F를 판별한다]
# 처음 답안
def solution(x):
x_to_str = list(str(x))
x_sum = 0
for i in x_to_str :
x_sum += int(i)
if x % x_sum == 0 :
answer = True
else :
answer = False
return answer
# 조건만 리턴해도 됨
def solution(x):
x_to_str = list(str(x))
x_sum = 0
for i in x_to_str :
x_sum += int(i)
return x % x_sum == 0- 처음 답을 작성할 때는 T/F 판별이었기 때문에 이 경우엔 T고 이 경우엔 F다 지정해서 그 값을 리턴해야 한다고 생각
- 하지만 조건을 거는 것 자체가 불리언 판단을 하기 때문에 조건만 리턴해도 같은 결과를 얻음
- 다른 풀이를 보다가 천재 발견
def solution(n):
return n%sum(int(x) for x in str(n)) == 0
[코드를 간결하게 쓰는 뇌구조란...]
- 요즘 항상 내 풀이 후에 다른 풀이 방법을 찾아보는 편인데, 어쩜 이런 천재가 많은지, 대체 뇌구조가 어떤건가요....
# 처음 답안
def solution(a, b):
answer = 0
if a <= b :
for i in range(a, b+1) :
answer += i
else :
for i in range(b, a+1) :
answer += i
return answer
# 1차 간결화
def solution(a, b):
answer = 0
for i in range(min(a,b),max(a,b)+1) :
answer += i
return answer
# 미친 천재
def adder(a, b):
return sum(range(min(a, b), max(a, b)+1))- 나는 단순히 a > b 와 a < b 로 나눠야 겠다고만 생각했는데, 결국 이것은 둘 중의 최소값과 최대값을 의미함
3. Python으로 데이터 분석하기
개인 실습
[groupby().집계 하면서 컬럼 이름도 바꾸고 싶은데요]
- df.groupby('col1')['col'].count().reset_index()를 하니 일단 오류가 났음 Soooo 당황
- 이렇게 데이터프레임을 만들면 컬럼 이름이 col1, col1 이렇게 그대로 설정되는데, 아마 같은 컬럼명이어서 문제 발생
- 그렇다면 집계하면서 동시에 컬럼 이름을 변경하는 방법을 찾자
# []에 해당하는 컬럼 값을 바꾸고 싶다면(이름 바꿀 컬럼 1개)
pickup_by_hour = uber_df.groupby('hour')['hour'].count().reset_index(name='count')
pickup_by_hour = uber_df.groupby('hour').agg(
total_count=('hour', 'count'),
).reset_index()
# 컬럼 여러개 이름을 바꾸고 싶은데?
pickup_by_hour = uber_df.groupby('hour').agg(
total_count=('hour', 'count'),
avg_distance=('distance', 'mean')
).reset_index()- 적용 범위가 넓은 agg 방법에 익숙해지려고 함 : agg ( 변경(생성) 컬럼 이름 = ('집계함수 대상 컬럼', '집계 함수') )
[한 그래프 안에 선 그래프를 여러개 그리기]
- 그래프를 그리다보면 시간에 따른 증감을 나타내긴 하는데... 회사별/아이템별로 나타내고 싶을 때가 많다
- matplotlib에서 그래프를 그릴 때, 그냥 한 판안에 계속 덧그려주면 됨
- 아래 데이터에서 시간별 count를 나타내는데, 그걸 Base별로 나눠서 그리고 싶었다(그치만 이제 한 그래프 안에)

(찾다보니 이걸 pivot 데이터 처럼 변형하여 하는 방법이 있었지만 난 몰라 난 그런 귀찮은 조작 싫어 데이터프레임이 바뀌기 싫대)
fig, ax = plt.subplots(figsize=(8,4))
for i in pickup_by_base_hour['Base'].unique() :
count_by_base = pickup_by_base_hour[pickup_by_base_hour['Base'] == i]
ax.plot(count_by_base['hour'], count_by_base['count'], label=i)
ax.set_xlabel('Hour of Day')
ax.set_ylabel('Total Pickup')
ax.set_title('Total Pickup by Hour')
ax.legend()
plt.show()- 각 Base를 필터링해서 그 프레임을 기반으로 그래프를 그리는 작업을 반복하면 됨
- 모든 Base 조건을 넣어 노가다해도 되지만, Base 고유값이 많으면 힘드니까 반복문을 사용하자
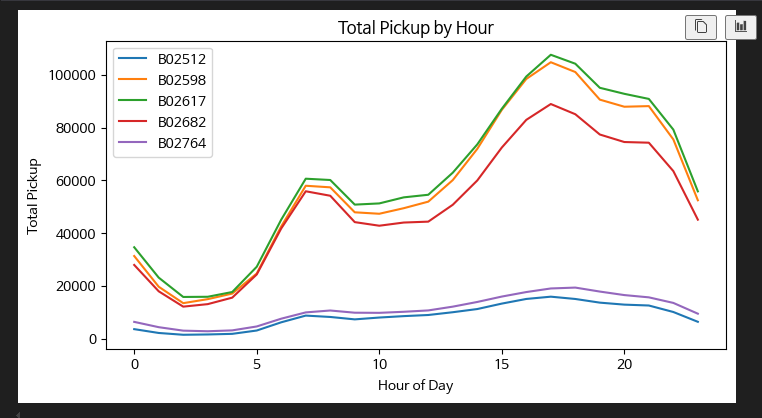
- 그래프를 계속 덧씌우기만 하면 된다니 생각보다 방법이 쉽다! 파이썬 재밌잖아!
개인 실습
[특정 데이터 타입의 컬럼만 추출하기]
- df.select_dtypes() : 문자, 정수, 실수, 날짜 등등 다양한 데이터 타입 중 원하는 타입의 데이터만 가져오고 싶을 때
- 생각해보니 머신러닝 모델을 만들 때, numeric 데이터만 필요했는데, 이럴때 유용하겠다는 생각
df.select_dtypes(include =[float,object], exclude=['int64'])
[특정 컬럼 기준 데이터 정렬하기]
df.sort_values(by=['col1', 'col2'], ascending=[False, True])
[특정값 포함 여부]
df['name'].isin(['kim', 'lee'])- name이라는 컬럼에 kim이나 lee중에 하나라도 있는지 확인
[loc의 또 다른 역할, 필터링 결과 추출]
- loc은 이름을 기준으로 데이터를 추출하는 방법이자, 조건을 입력하여 그에 해당하는 데이터만 추출할 수도 있음
- 조건이 하나인 경우, 조건이 있으면서 특정 컬럼값만 보고싶은 경우, 조건이 여러개인 경우 모두 가능
# True/False 결과값 가지는 조건 설정
cond = (df['age'] >= 70)
cond
#loc을 활용하여 True인 행만 필터링해서 가져오기(모든 컬럼 불러옴)
df.loc[cond]
# 위에서 추출한 조건 True인 데이터 중, age 컬럼만 가져오기
df.loc[cond, 'age']
# 조건 여러개
# 조건1
cond1 = (df['fare'] > 30)
# 조건2
cond2 = (df['who'] == 'woman')
df.loc[cond1 & cond2]
df.loc[cond1 | cond2]
[df.copy()를 써야 하는 이유, df2 = df와는 다른 것]
- 가장 큰 목적은 수많은 분석 과정에서 원본 데이터를 유지하기 위해서임
- df2 = df는 shallow copy라고 해서, df를 수정해도 df2에 영향이 가고 df2를 수정해도 df에 영향기 가기 때문에 원본을 유지할 수 없음
- df2 = df.copy(dee=True) : deep은 True값이 기본값인데, 이는 df와 df2가 서로 영향을 주지 않음을 뜻함
- deep=False를 하면 shallow copy인 것
[냅다 중간에 컬럼을 추가하고 싶다면 insert()]
- df.insert(loc, column, value, allow_duplicates=False)
- loc : 삽입될 열의 위치(파이썬식 순서, 4번째면 3)
- column: 삽입될 열의 이름
- value: 삽입될 열의 값
- allow_duplicates: {True or False} 기본값은 False. True일경우 중복 열의 삽입을 허용
df.insert(3,'col4',df2['col4'])
[행,열 삭제]
# 행 삭제
df.drop(index='row3', inplace = True)
# 열 삭제
df.drop(columns='col3', inplace = True)- 행의 이름과 열의 이름만 넣어주면 됨
[결측값(null,nan) 대체]
df.fillna('A',inplace=True)'데이터 부트캠프 - Today I Learned' 카테고리의 다른 글
| [스파르타 내일배움캠프 / 데이터 분석 트랙] WIL(Weekly I Learned)_4주차 (0) | 2024.12.22 |
|---|---|
| [스파르타 내일배움캠프 / 데이터 분석 트랙] TIL(Today I Learned)_4주차_24.12.20 (3) | 2024.12.20 |
| [스파르타 내일배움캠프 / 데이터 분석 트랙] TIL(Today I Learned)_4주차_24.12.18 (3) | 2024.12.18 |
| [스파르타 내일배움캠프 / 데이터 분석 트랙] TIL(Today I Learned)_4주차_24.12.17 (3) | 2024.12.17 |
| [스파르타 내일배움캠프 / 데이터 분석 트랙] TIL(Today I Learned)_4주차_24.12.16 (1) | 2024.12.16 |